Jeder Scanner kann als Dokumentenscanner verwendet werden. Und das fast ohne eine Abhängigkeit zum angemeldeten Benutzer und fast ohne Einsatz von komplizierter Zusatzsoftware.
Egal ob PDF-Dateien mit Texterkennung (engl. OCR), E-Mail an Sie selbst, andere Empfänger oder gar mit Cloud Anbindung, damit Sie auch von Unterwegs mit Ihrem Mobilgerät, Tablet oder Handy, Fotos zu Word, Excel und PDF Dokumenten wandeln wollen.
Wie Sie Ihr Gerät zu einem großen Dokumentencenter aufwerten – erfahren Sie in diesem Artikel.
Inhaltsübersicht
Einleitung
Haben Sie auch einen Scanner und wollen Ihre Dokumentablage digitalisieren? Ob HP DeskJet oder Samsung Multifunktionsgerät. Vieles steht und fällt bei sogenannten kleinen Office Geräten mit der dazugehörigen Software. Ein Update hier – eine Einstellung da und schon klappt es nicht mehr wie zuvor mit Ihren Dokumenten.
Das nachfolgende Skript kann Ihre Anforderungen konstant und erweiterbar umsetzen.
Anforderungen
Scanner als Eingabemedium
Grundsätzlich kann jeder Scanner verwendet werden, sofern er Dokumente auf Knopfdruck lokal oder auf das Netzwerk speichern kann.
USB Geräte (Twain Treiber)
Mithilfe der Basistreiber – also ohne der Herstellersoftware – können an den meisten Geräte bereits die lokalen Tasten auf dem Scanner angesprochen werden. Dadurch kann der Scanvorgang nach dem ein- oder auflegen eines Dokuments gestartet werden. Der PC übernimmt die weiteren Schritte.
Windows, MAC oder Linux Computer
Abhängig vom Betriebssystem kann der Tastendruck auf dem Scanner durch den Treiber interpretiert werden. Die weitere Verarbeitung kann unter Linux mit dem SANE Daemon realisierbar werden. In Mac OS befindet sich der Photo Scanner im App Store oder für Microsoft Windows kann das im Betriebssystem verfügbare Scanprogramm für die Verarbeitung der Bilddaten genutzt werden. Aber auch mit deinem raspberry pi zero lassen sich diverse Scanner passend anbinden, die gescannten Dokumente empfangen und lokal speichern.
Zur Vereinfachung konzentriert sich die nachfolgende Lösung ausschließlich auf die Windows Bordmittel.
Netzwerkfähige Geräte
Moderne Laserdrucker oder Multifunktionsgeräte ermöglichen das Speichern von Dokumenten auf Netzlaufwerken, via FTP oder WebDAV. So gelangen die Bildinformationen auf Ihren Computer.
Handykamera als Eingabemedium
Die Verarbeitung mit einem Handy stellt heutzutage kein Problem dar. Im Google Play / Apple Store finden sich zahlreiche kostenpflichtige oder kostenlose Programme.
Doch was ist, wenn Sie nicht das Geld in eine App investieren wollen, eine übergreifende und Integriere Lösung suchen, Ihre Daten keinem Drittanbieter anvertrauen wollen, oder dies aus Datenschutz nicht dürfen. Hierfür benötigen Sie lediglich Ihre Kamera App zum Speichern der Bilddaten.
Cloud Anbindung
Eine Cloudanbindung stellt den Vermittler zwischen den unterschiedlichen Eingabegeräten dar. Die gescannten Daten können so vom erzeugenden Gerät auf den hier vorgestellten Scan Prozessor transferiert werden.
- Cloud als Schnittstelle
Egal für welche Cloudanbindung Sie sich entscheiden.
- Own Cloud / Next Cloud
- Microsoft OneDrive
- Amazon / Web.de / GMX Drive
- Box.com
- Magenta Cloud
- Dropbox
- Citrix Sharefile
- WebDAV Share
- uvm….
Die meisten Lösungen haben meist betriebssystemspezifische Anwendungen zur Synchronisation der Daten.
Damit können Ihre digitalisierten Dokumente, an den hier vorgestellten und nachfolgend beschriebenen Scan Prozessor, zur weiteren Verarbeitung übertragen.
Skript als Scan Prozessor
Zur automatischen Verarbeitung von Daten sind Skripte besonders gut geeignet. Sie stellen die ideale Basis für eine strukturierte Verarbeitung der synchronisierten Daten dar. Zur Vereinfachung wird nachfolgend lediglich Microsoft PowerShell und ABBYY Professional mit Hot Folder als automatische Verarbeitungslösung beschrieben.
Warum?
- ABBYY Professional wird oftmals bei den meisten Allround Dokumentenscannern als Dreingabe mitgeliefert.
- Microsoft Betriebssysteme werden sehr häufig bei KMU eingesetzt
Sollten Sie diese Basis nicht haben, ist nichts verloren. Die Skriptlogik lässt sich mit wenig Mühe auch für Ihr Betriebssystem und Ihre individuelle Software anpassen.
Sie möchten die kostenfreie Tesseract Open Source OCR (vgl. https://github.com/tesseract-ocr/tesseract) verwenden? Kein Problem. Das nachfolgende Skript arbeitet Ordnerbasiert und lässt daher eine logische Anpassung zu.
Logisches Schaubild der Lösung
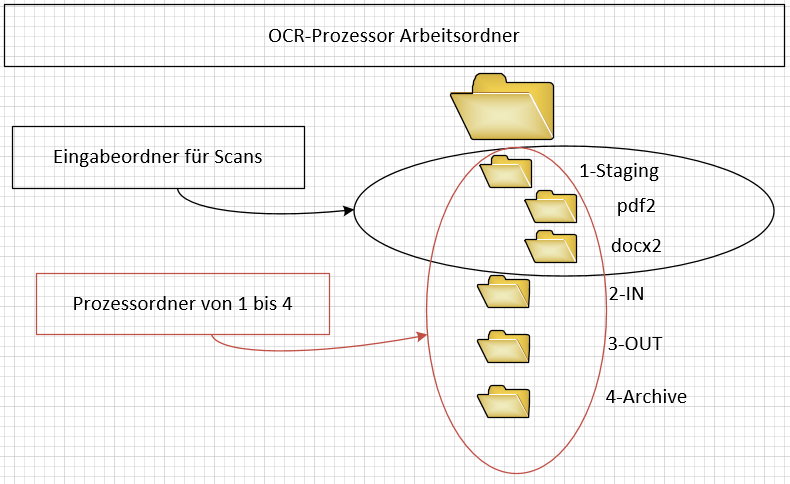
Beschreibung
Eingabeordner
Die Eingabeordner entsprechen den lokalen Ordnern auf einem Windows Computer. Diese können entweder über einen FTP Dienst wie Filezilla-Server, einer Windows Datei-Freigabe oder einer Cloud Sync mit den Bildinformationen – also den Scanergebnissen – befüllt werden. Die darunter liegenden Ordner werden nach Dokumententyp der Ausgabedatei gefolgt von der internen Nummer der Zieladresse erstellt. Dies stellt die Basis für die weitere Verarbeitung in einem Skript dar.
Die Prozessordner
Die Ordner IN, OUT und Archive werden durch den OCR Prozessor angesprochen. Nachdem eine Datei erfolgreich im Eingabeordner abgelegt wurde, wird diese durch das Script in den IN Ordner verschoben. Hierbei wird die Eingabedatei umbenannt, sodass diese nach Ausgabe durch den OCR Prozesses im OUT Ordner wieder identifiziert werden kann.
Die Dateibenennung wird wie folgt aufgebaut:
- Eingabedatei im Staging Ordner
- Dateiname darf entsprechend der gewählten Eingabelösung frei gewählt / variiert werden.
- IN Ordner
- Die Eingabedateien werden mit einer fortlaufenden internen Nummer des Skripts, gefolgt vom Namen des Quellordners hierhin verschoben und umbenannt.
- Beispiel für Dateinamen: 00001pdf2.jpg
- Erklärung: „00001“ als interne Nummer gefolgt von „pdf2“ Name des Quellenordners
- Dateiendungen werden übernommen, sofern diese von der gewählten OCR Lösung bearbeitet werden können. Sofern notwendig können hier zusätzliche Tools wie gif2png oder png2jpg je nach Anforderung die Quelldatei vorbereiten.
- OCR Lösung zwischen IN- und OUT-Ordner
- Die gewählte OCR Lösung wie ABBYY Hotfolder (https://help.abbyy.com/de-de/finereader/15/user_guide/automation), oder auch Tessract-OCR (https://github.com/tesseract-ocr/) werden durch eigene interne Trigger, oder durch das Skript angestoßen. Dadurch wird eine Verarbeitung aus dem IN in den OUT Ordner durchgeführt. Die ausgegebenen Dateien werden mit identischen Dateinamen im Ausgabeordner wieder abgelegt.
- Endverarbeitung zwischen OUT- und Archiv Ordner
- Nach erfolgter Verarbeitung wird die ausgegebene Datei, durch das Skript als E-Mail versendet. Hierbei wird der im Skript hinterlegte Standardabsender verwendet. Die im Script konfigurierbare Zieladresse wird dann mit einer E-Mail und der angehängten verarbeiteten Datei und einem Standardtext benachrichtigt.
- Beispiel: 00001pdf2.jpg
- Erklärung: Dateianhang PDF an parametrisierte E-Mailadresse mit der ID 2
OCR Lösungen im Vergleich
Es gibt viele Hersteller welche OCR Lösungen anbieten. Alle haben jeweils Ihre Vor- und Nachteile. Eine Lösung mittels Tesseract OCR ist kostengünstig und kann sehr gut in bestehende Lösungen integriert werden. Die Lernfunktion kollidiert leider meist mit der persönlichen Motivation, einer schnellen und guten Lösung.
Lösungen wie Adobe Acrobat, FreePDFxChange oder ähnliche besitzen keine oder eine nicht so gut integrierbare automatische Verarbeitungsschnittstelle. Tools wie GhostMouse, RoboTask, KlickBot oder AutoIt können dazu verwendet werden, Dateien automatisiert zu verarbeiten. Der Nachteil hierbei ist immer, dass ein angemeldeter Benutzer durch „aufpoppende Fenster“ oder fremde Mausbewegungen gestört wird. Zudem sind diese Co-Automatisierungslösungen meist wegen der gewählten Bildschirm-Auflösung sehr fehleranfällig und wartungsintensiv. Daher habe ich mich für die ABBYY HotFolder Lösung entschieden. Für einen einmaligen Kauf-Betrag von derzeit 299 EUR (Corporate Edition) vereint diese alle notwendigen Vorteile.
Vorteile:
- HotFolder für Prozessbasierte Dokumentenverarbeitung
- Keine Benutzerinteraktion zur Verarbeitung notwendig
- Ausgabeformate wie Excel, PowerPoint, Word und PDF
Nachteile:
- Maximal 5000 Seiten im Monat
- Maximal 2 CPU Kerne
Damit stellt die ABBY Hot-Folder Lösung eine optimale, virtualisierbare und automatische OCR Lösung für KMU dar.
PowerShell Skript incl. ABBYY Hot Folder als Windows Plattform Lösung
Das Skript kann incl. Ordnerstruktur HIER <LINK> heruntergeladen werden. Nach erfolgter Parametrisierung, muss eine regelmäßige Ausführung mittels Aufgabenplanung erfolgen.
Vor- und Nachteile der PowerShell Lösung im Überblick
Nachteile
- Einmaliger Aufwand für Einrichtung und Parametrisierung
- Ggf. Wartungsaufwände nach Implementierung
- Keine Just in Time Konvertierung // zeitlicher Versatz
Vorteile
- Starke Individualisierung durch Cloud Anbindung möglich
- Kostenvorteil gegenüber Kopiererlösungen
- Freie Kopierer- und Scanner Auswahl ohne Hardwarebindung
Lessons Learned // Lösungen aus der Praxis
In der Realisierung haben sich folgende Punkte als zielführend erwiesen
- Verwendung eines dedizierten virtuellen Systems
Eine geteilte Nutzung ist zwar möglich, jedoch stark fehleranfällig. In Kundeninstallationen hat sich gezeigt, dass Computer gerne abends heruntergefahren werden. Dies stört den Ablauf einer solchen Automatisierung. Das Parallele Verwenden von ABBYY auf dem Zielcomputer stört gelegentlich bei Updates, sodass der HotFolder nicht immer zuverlässig seinen Dienst verrichtet. Die Verwendung eines alten nicht aktiv verwendeten Computers oder einer virtuell verfügbaren Windows Version hat sich als zuverlässige Lösung herauskristallisiert.
- Eigener Benutzeraccount bei CloudSync
Bei der Nutzung von Cloud Diensten müssen Zugangsdaten für den Sync Client eingegeben werden. Wenn der verwendete Benutzeraccount gesperrt oder temporär nicht verfügbar ist, wird die Dateiübertragung gestört. Das Verwenden eines dedizierten Benutzerkontos auf Windows als auch beim Cloud Dienst stellt den Zugriff als auch die Dateiübertragung ohne Dateikonflikte und Zugriffsprobleme sicher.
Zusammenfassung
Nach erfolgter Parametrisierung und Implementierung läuft diese Lösung bereits bei einer Handvoll Kunden im dritten Jahr fehlerfrei, stabil und zuverlässig. Die zuvor erwähnten Nachteile wurden als Stärken der Lösung herausgearbeitet, sodass interne Prozesse als auch die Systemlandschaft darauf angepasst werden konnten.
Besonders freut es mich, dass eine Zusammenarbeit mit einem Individualsoftwareanbieter auf genau dieser Lösungsidee basiert und bereits bei zahlreichen Kunden als ergänzende Lösung Anklang findet.
Sollten Sie zu diesem Artikel, der hier vorgestellten Lösung, oder anderweitige Fragen haben, stehe ich Ihnen gerne jederzeit zur Verfügung.
Mehr zu diesem Beitrag
Quellen / Einzelnachweise
- Abbyy Automation Webseite (https://help.abbyy.com/de-de/finereader/15/user_guide/automation)
- Tesseract-OCR auf Github (https://github.com/tesseract-ocr/)
Weiterführende Links
- keine
Änderungshistorie
| Erstellt: 2021-02-15 | Zuletzt geändert: 2021-02-15 |
| Änderungshistorie: – 2021-02-15: Basis – Layout + Text |